NBA Final 2024 Process Mining
September 11, 2024
Project Introduction 👋🏽
Inspired by Kröckel and Bodendorf (2020), this analysis will use R to explore process mining on a subject I am fond of - basketball. I have played basketball all my life, although my failing left knee means I play infrequently in my older age.
I will be analysing game 5 of the 2024 NBA final between Dončić, Dallas Mavericks and Tatum, Boston Celtics. Well done Celtics 🍀, who last won a championship 16 years ago. I will avoid findings which could just as easily be found in a games summary statistics and focus on what unique insights process mining provides. Let us start with the data.
# Load packages
library(tidyverse)
library(bupaverse)
library(patchwork)
library(viridis)
library(DT)
library(psmineR)
# Global settings
knitr::opts_chunk$set(
echo = TRUE,
message = FALSE,
warning = FALSE
)
theme_set(theme_minimal(base_family = 'serif'))
# Get data
nba_2024_g5_pm_data <- read_csv('./input/nba-final-2024-game-5.csv', col_names = TRUE) %>%
mutate(
resource_id = case_when(
resource_id == 'Luka Doncic' ~ 'Luka_Dončić',
resource_id == 'Kristaps Porzingis' ~ 'Kristaps_Porziņģis',
TRUE ~ resource_id)
)
Data Treatment
The data collation was a manual effort, a labour of love. After watching game 5 of the 2024 NBA finals I painstakingly noted down each activity along with the timestamp.
To add assurance to this data set I checked each activity available on nba.com/play-by-play (2024) matched on timestamp and cross checked the summary player stats against nba.com/box-score (2024).
A few self imposed rules during data creation:
-
To define the process under analysis, one end to end run or ‘case’ ends with a shot
-
For free throws the case ends at the last free throw attempt
-
Unless specified from the nba website I have timestamped at the beginning of each activity
Data is available on Kaggle or Github
Create Eventlog
An eventlog in process mining is a structured collection of recorded events that represent the execution of activities usually within a business process, in this context, an NBA game.
It typically contains information such as the event type, timestamp, case identifier, and other relevant attributes, serving as the primary input for process mining techniques to discover, monitor, and improve actual processes.
Once an event log object has been created, the object can be used across multiple analyses.
nba_final_g5_eventlog <- nba_2024_g5_pm_data %>%
mutate(lifecycle_id = 'complete',
timestamp = ymd_hms(paste0('20240617 ', timestamp))) %>%
eventlog(case_id = 'case_id',
activity_id = 'activity_id',
activity_instance_id = 'seq',
lifecycle_id = 'lifecycle_id',
timestamp = 'timestamp',
resource_id = 'resource_id',
order = 'seq',
validate = TRUE)
Analyses
Control-Flow
Control flow in process mining refers to the sequence and decision points of activities within a process. This perspective explores the flow of the game.
Traces
Traces are the distinct processes of an eventlog, in this context, a play which starts at the beginning of a quarter of post shot attempt until another shot attempt.
Coverage
Reviewing the trace coverage relative to cases let us us see if the same plays are used throughout or if plays are variable. The plots display relative frequencies above 0.02 to remove the plot tail and make for better viewing.
log_trace <- nba_final_g5_eventlog %>%
trace_coverage('trace') %>%
filter(relative > 0.02) %>%
plot() +
theme(legend.position = 'top') +
scale_fill_viridis('Relative Frequency',
option = 'D',
direction = -1) +
scale_y_continuous(limits = c(0, 0.45),
breaks = seq(0, 0.45, 0.05)) +
scale_x_continuous(breaks = seq(0, 1, 0.2)) +
labs(title = 'Play variance') +
ylab('')
united_log_trace <- nba_final_g5_eventlog %>%
act_unite(
pass = c(
'pass-to-assist',
'pass',
'pass-turnover',
'pass-to-start-quarter'
),
dribble = c('dribble', 'dribble-turnover'),
rebound = c('defensive-rebound', 'offensive-rebound'),
shot = c('shot-miss', 'shot-make')
) %>%
trace_coverage('trace') %>%
filter(relative > 0.02) %>%
plot() +
theme(legend.position = 'top') +
scale_fill_viridis('Relative Frequency',
option = 'D',
direction = -1) +
scale_y_continuous(limits = c(0, 0.45),
breaks = seq(0, 0.45, 0.05)) +
scale_x_continuous(breaks = seq(0, 1, 0.2)) +
labs(title = 'Play variance with unified activities') +
ylab('')
(log_trace + united_log_trace) +
plot_layout(axes = 'collect')
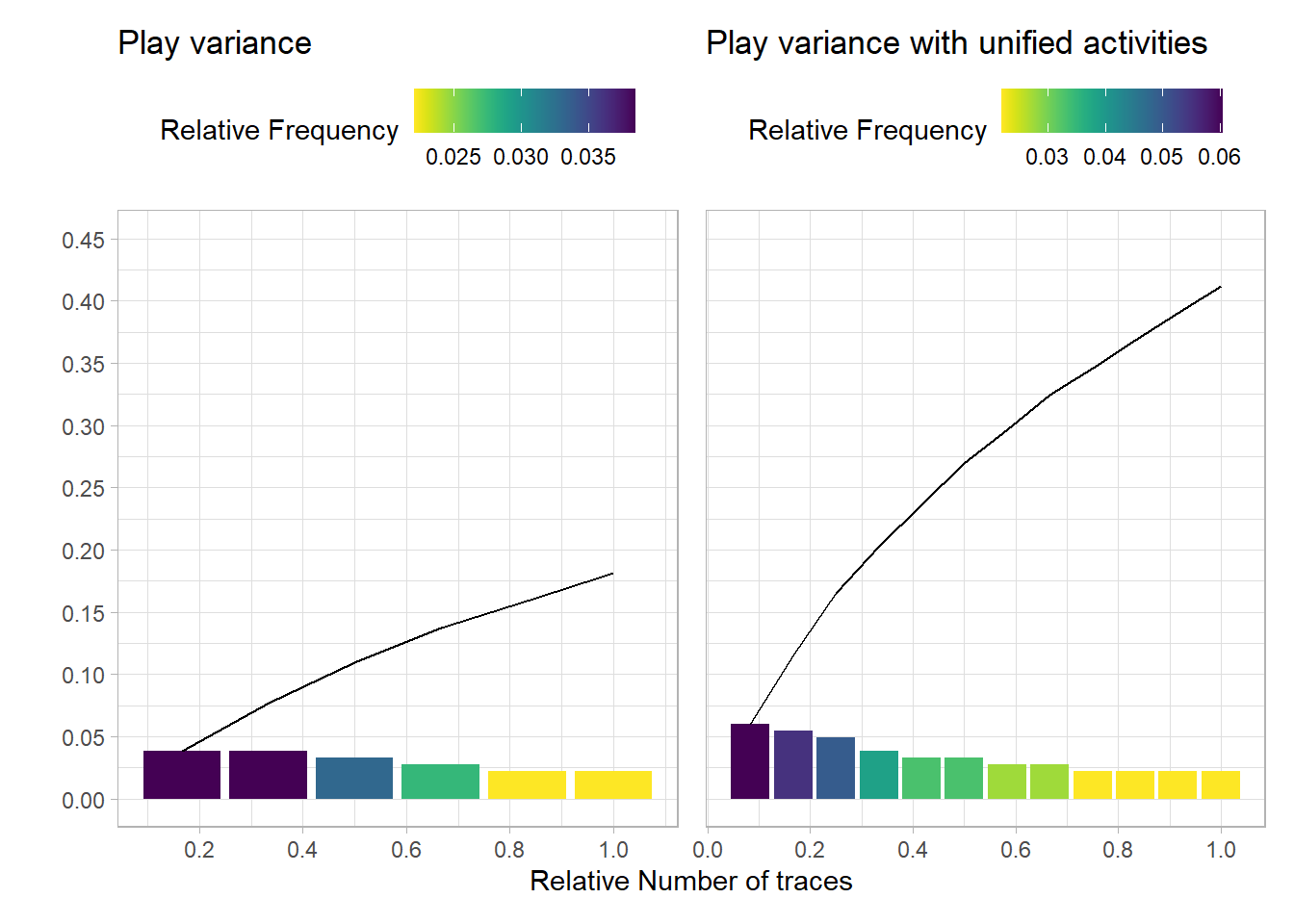
As the left plot displays a max relative frequency of 0.03, the plays of this game varied considerably. Even when grouping activities e.g. dribble and dribble-turnover both set as dribble, a max relative frequency of 0.06 as shown in the right plot.
With more detailed data around off the ball movements and data on many more games, perhaps you could use trace coverage analysis to: - Indicate if systematic plays are used, shown by an increase in the relative frequency - Compare across teams and games to see if this metric shares patterns with tradition metrics i.e. win/loss, plus/minus etc
Team Trace Length
Reviewing the trace sizes for each team i.e. The number of activities used until a shot attempt.
shot_made_plot <- nba_final_g5_eventlog %>%
filter_activity_presence('shot-make') %>%
group_by(teams_play) %>%
trace_length('log') %>%
plot() +
theme(strip.background = element_rect(fill = viridis::viridis(1, direction = 1))) +
geom_jitter(alpha = 0.7, size = 2) +
geom_boxplot(fill = viridis::viridis(1, alpha = 0.6, direction = -1),
colour = '#000000') +
stat_boxplot(geom = 'errorbar', linetype = 'dashed', width = 0.1) +
scale_y_continuous(limits = c(0, 18)) +
labs(title = 'Teams Traces by Shot Made')
shot_miss_plot <- nba_final_g5_eventlog %>%
filter_activity_presence('shot-miss') %>%
group_by(teams_play) %>%
trace_length('log') %>%
plot() +
theme(strip.background = element_rect(fill = viridis::viridis(1, direction = 1))) +
geom_jitter(alpha = 0.7, size = 2) +
geom_boxplot(fill = viridis::viridis(1, alpha = 0.6, direction = -1),
colour = '#000000') +
stat_boxplot(geom = 'errorbar', linetype = 'dashed', width = 0.1) +
scale_y_continuous(limits = c(0, 18)) +
labs(title = 'Teams Traces by Shot Miss')
(shot_made_plot + shot_miss_plot) +
plot_layout(axes = 'collect')
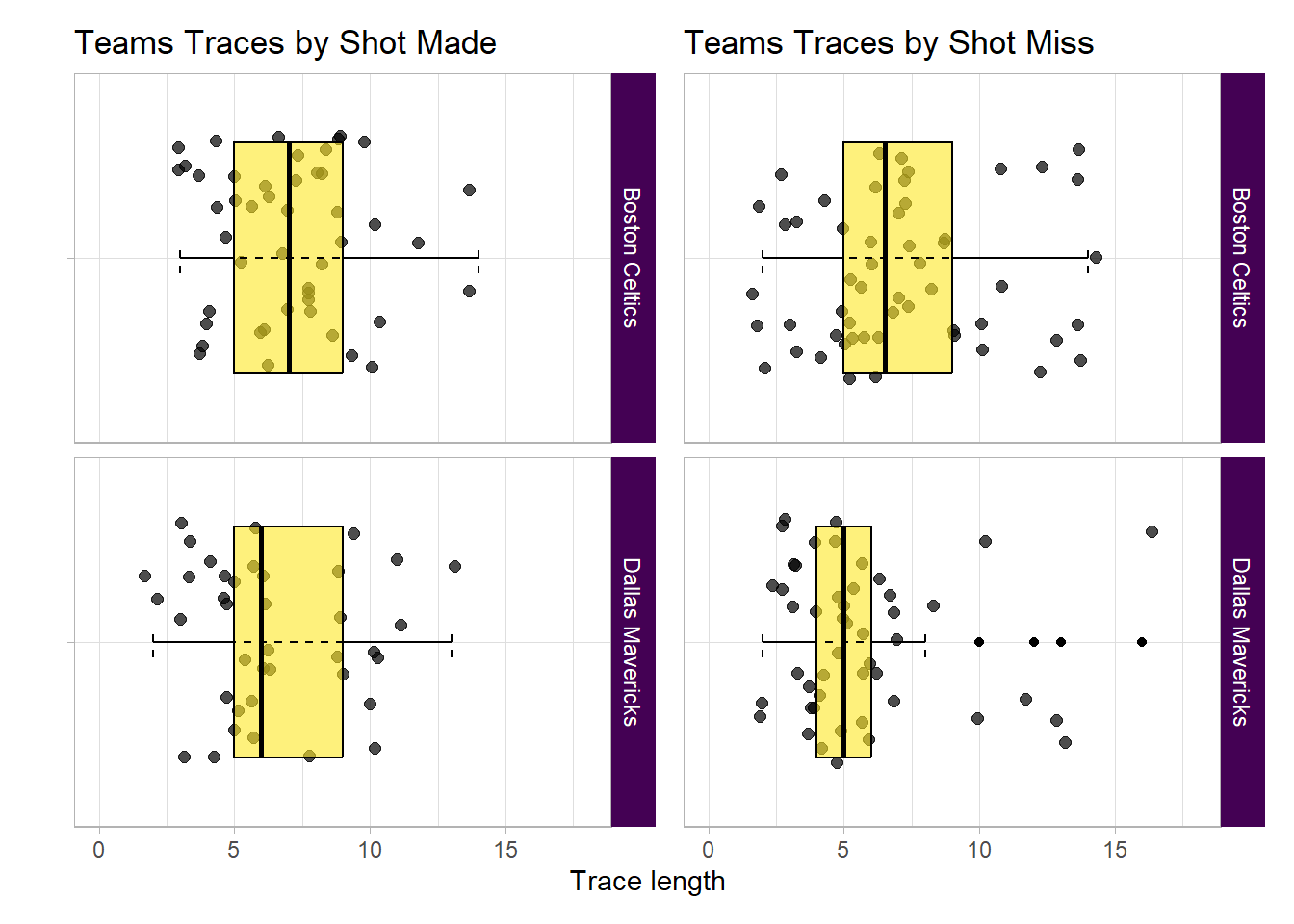
All look similar except Dallas for plays which end in a miss. Lets look into this further by spliting Dallas traces by quarter.
nba_final_g5_eventlog %>%
filter(teams_play == 'Dallas Mavericks') %>%
filter_activity_presence('shot-miss') %>%
group_by(quarter) %>%
trace_length('log') %>%
plot() +
theme(strip.background = element_rect(fill = viridis::viridis(1, direction = 1))) +
geom_jitter(alpha = 0.7, size = 2) +
geom_boxplot(fill = viridis::viridis(1, alpha = 0.6, direction = -1),
colour = '#000000') +
stat_boxplot(geom = 'errorbar', linetype = 'dashed', width = 0.1) +
scale_y_continuous(limits = c(0, 18)) +
labs(title = 'Dallas Traces by Shot Miss & Quarter')
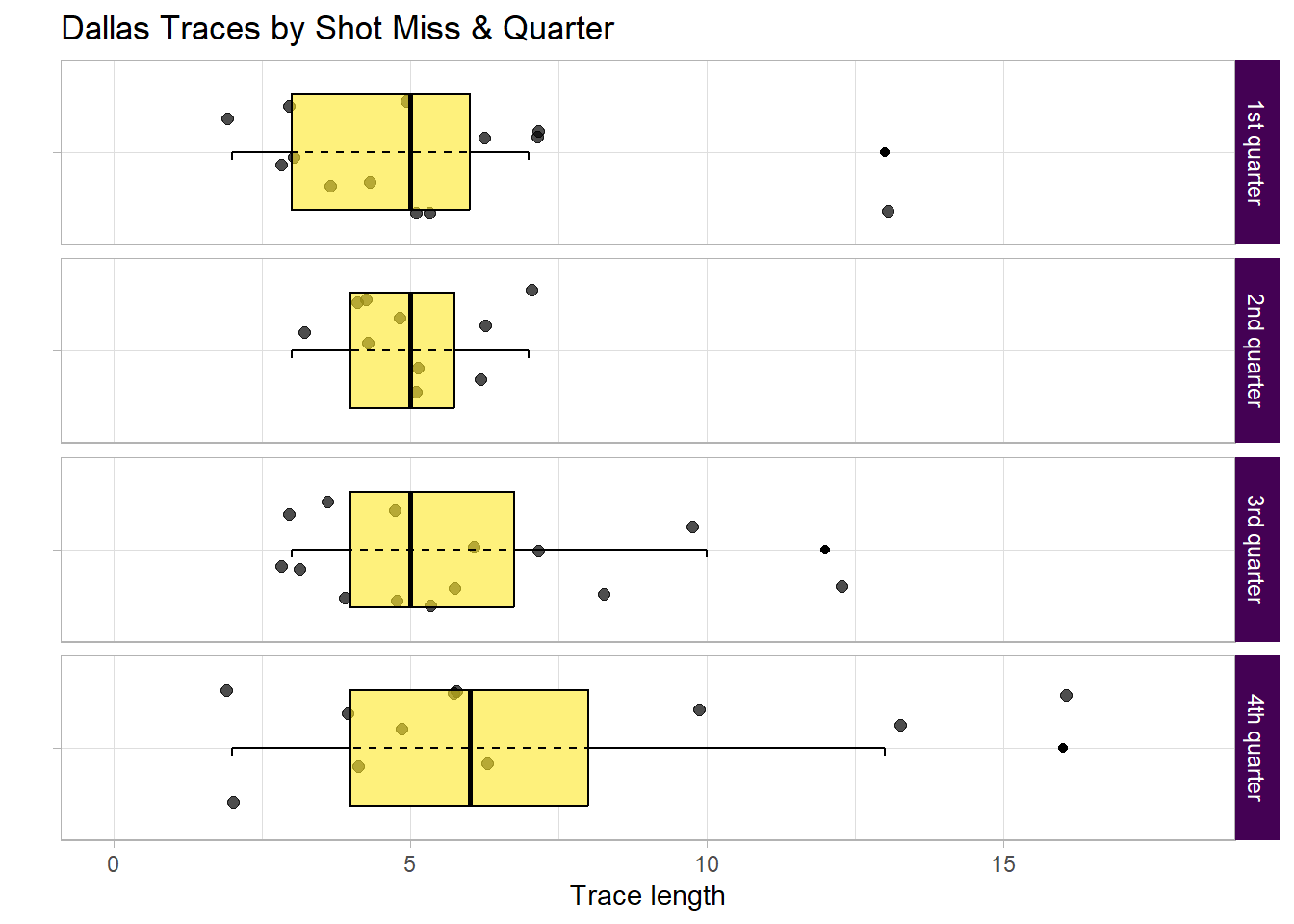
The 4th quarter has higher average and max trace lengths at a time when they needed to make a push.
There could be multiple reasons as to why, perhaps Boston played brilliant defence forcing Dallas to pass more in order to shift the defence and make space.
Regardless this ran down the clock limiting the number of available opportunities to reduce the deficit.
Let us view that 4th quarter outlier process to see why.
longest_trace <- nba_final_g5_eventlog %>%
filter(teams_play == 'Dallas Mavericks') %>%
filter_activity_presence('shot-miss') %>%
filter_trace_length(percentage = 0.01) %>%
count(case_id, sort = TRUE) %>%
head(1) %>%
pull(case_id)
nba_final_g5_eventlog %>%
filter_case(cases = longest_trace) %>%
as.data.frame() %>%
select(case_id, seq, activity_id, player_team, teams_play) %>%
datatable(class = c('compact', 'hover', 'row-border'),
rownames = FALSE,
options = list(dom = 't'))
This outlier is explained by how a play is defined by a shot attempt. Boston held position at the onset but turned over possession to Dallas, shortly after Dallas made a shot attempt.
Precedences
Reviewing the activity process matrix allows for investigation into antecedent and consequential activities. Each activity row will sum to 100%.
nba_final_g5_eventlog %>%
process_matrix(type = frequency('relative-antecedent')) %>%
plot() +
theme(legend.position = 'top') +
scale_fill_viridis(option = 'D', name = 'Relative Antecedence', direction = -1)
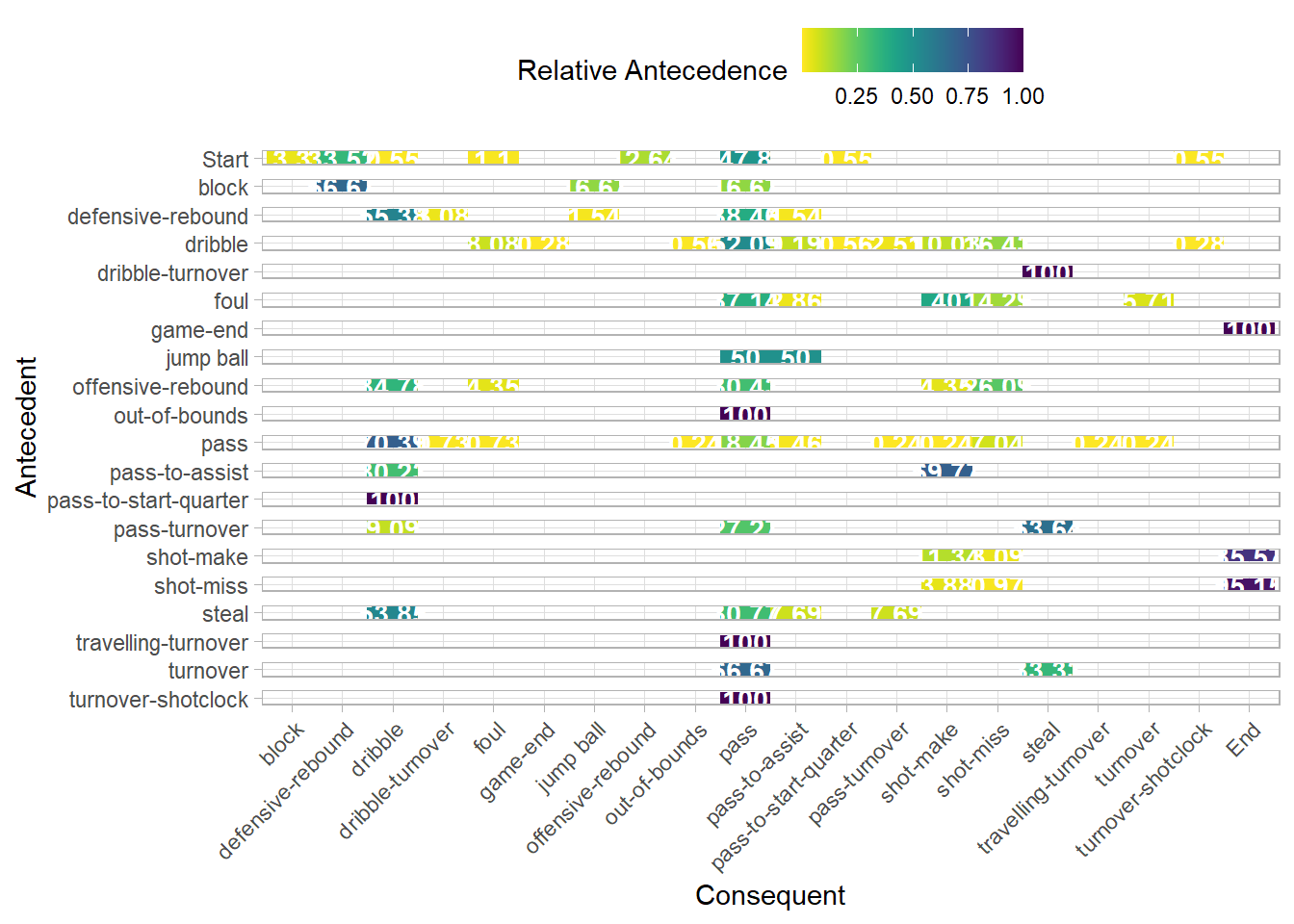
Across the game ~70% of all passes were followed by a dribble whilst ~20% of the time it was followed by another pass. Additional data and further analysis could shed light on, if these figures typified finals or playing styles of NBA teams.
~55% of the time a defensive rebound was followed by a dribble, and ~38% a pass. Your taught to grab the rebound and look for the outlet (at least in the United Kingdom) yet in this game the dribble was preferred. If you had player positions you may look to investigate if a lack of outlet options was the reason or perhaps the rebound was caught closer to the 3pt line than under the rim so it made more sense to move the ball up the court for a fast break.
Performance
Performance analysis typically involves metrics such as time to complete activity, time in between each activity, and total time of process to understand the factors affecting process performance.
Throughput Time
This analysis is limited by the time stamps collected. If I had start and end times of each activity, more granular analysis could be performed. As it stands only total time across process is available, also know as throughput time.
throughput_make_plot <- nba_final_g5_eventlog %>%
group_by(teams_play) %>%
filter_activity_presence('shot-make', method = 'none') %>%
throughput_time('log', units = 'secs') %>%
plot() +
theme(strip.background = element_rect(fill = viridis::viridis(1, direction = 1))) +
geom_jitter(alpha = 0.7, size = 2, ) +
geom_boxplot(fill = viridis::viridis(1, alpha = 0.6, direction = -1),
colour = '#000000') +
stat_boxplot(geom = 'errorbar', linetype = 'dashed', width = 0.1) +
scale_y_continuous(limits = c(-5, 45)) +
labs(title = 'Teams Traces by Shot Make')
throughput_miss_plot <- nba_final_g5_eventlog %>%
group_by(teams_play) %>%
filter_activity_presence('shot-miss', method = 'none') %>%
throughput_time('log', units = 'secs') %>%
plot() +
theme(strip.background = element_rect(fill = viridis::viridis(1, direction = 1))) +
geom_jitter(alpha = 0.7, size = 2) +
geom_boxplot(fill = viridis::viridis(1, alpha = 0.6, direction = -1),
colour = '#000000') +
stat_boxplot(geom = 'errorbar', linetype = 'dashed', width = 0.1) +
scale_y_continuous(limits = c(-5, 45)) +
labs(title = 'Teams Traces by Shot Miss')
(throughput_make_plot + throughput_miss_plot) +
plot_layout(axes = 'collect')
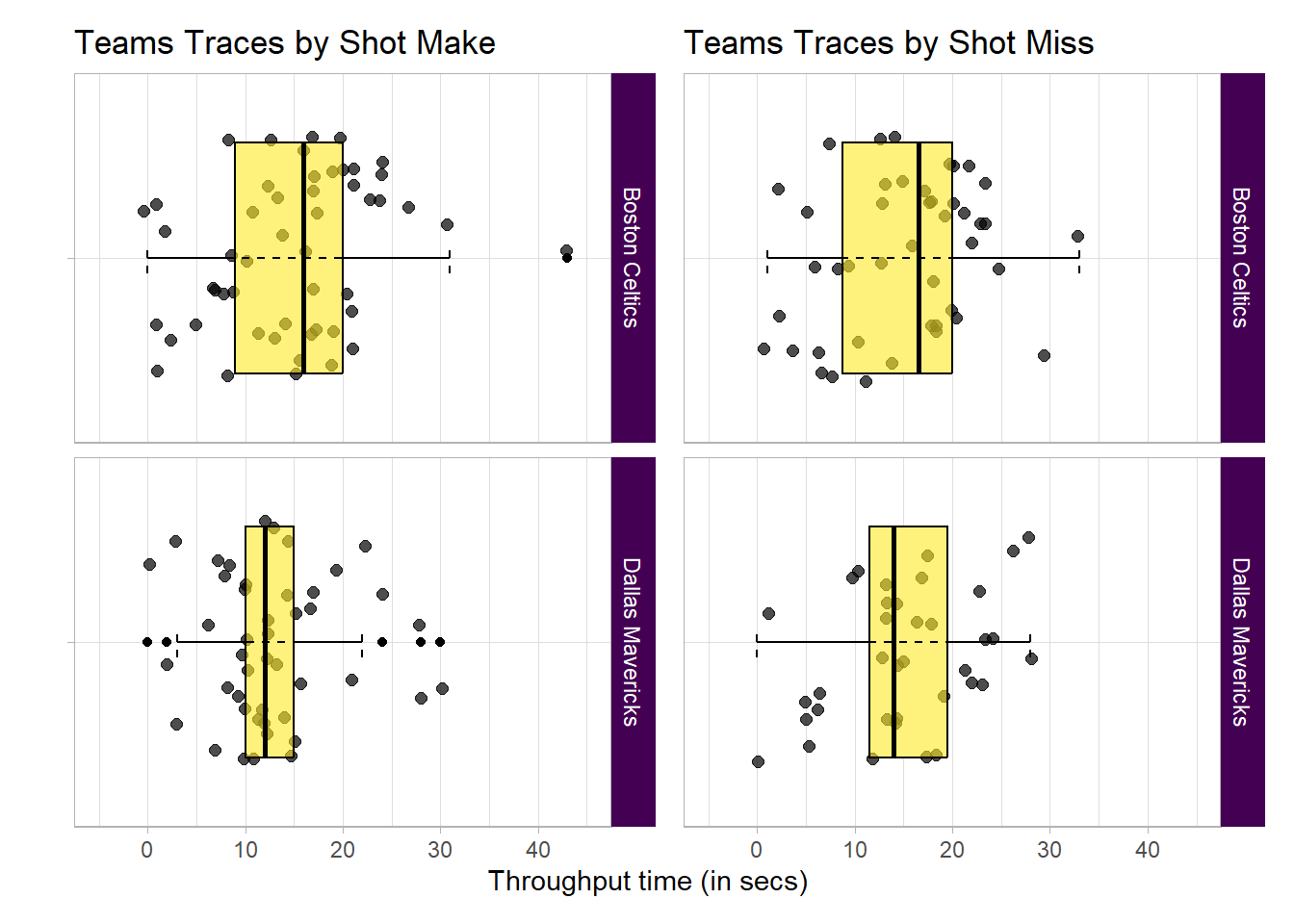
-
Bostons interquartile range is wider than Dallas’s, 50% of Bostons plays are more varied in time than 50% of Dallas’.
-
For shots made by Dallas the interquartile range is half that of Boston. 50% of Dallas’s plays were quick, perhaps rushed due to score deficit.
Process Map
Process mining isn’t complete without a process map. Split by team plays, you could dig for many insights looking across both maps.
Boston Celtics
nba_final_g5_eventlog %>%
filter(teams_play == 'Boston Celtics') %>%
process_map(
type_nodes = frequency('absolute'),
type_edges = performance(mean, 'secs'),
rankdir = 'TB'
)
Dallas Mavericks
nba_final_g5_eventlog %>%
filter(teams_play == 'Dallas Mavericks') %>%
process_map(
type_nodes = frequency('absolute'),
type_edges = performance(mean, 'secs'),
rankdir = 'TB'
)
A few noteworthy insights:
-
Boston was more industrious than Dallas. Having completed more passes, dribbles, rebounds, blocks etc
-
Boston was 1 second quicker on average to make a shot attempt after a defensive rebound.
-
Both teams passed the ball with similar average times: Boston with 1.2 seconds and Dallas 1.51 seconds, for passes not leading to an assist. Boston 2.31 seconds and Dallas 2.5 seconds for passes leading to an assist. In both cases Boston were on average quicker and sharper in moving the ball.
Spectra
Referenced in bupaverse (2024), Denisov, Fahland, and Aalst (2018) provides another avenue to analyse performance. What the authors term ‘performance spectra’ defined as ‘The Performance Spectrum is a fully detailed data structure and visualization of all cases over all segments over time’ provides a taxonomy of performance patterns.
nba_final_g5_eventlog %>%
ps_detailed(segment_coverage = 0.15, classification = 'teams_play') +
scale_colour_viridis_d(name = 'Team Plays') +
theme(
strip.background = element_rect(fill = viridis::viridis(1, direction = 1)),
strip.text = element_text(colour = '#ffffff'),
legend.position = "top"
)
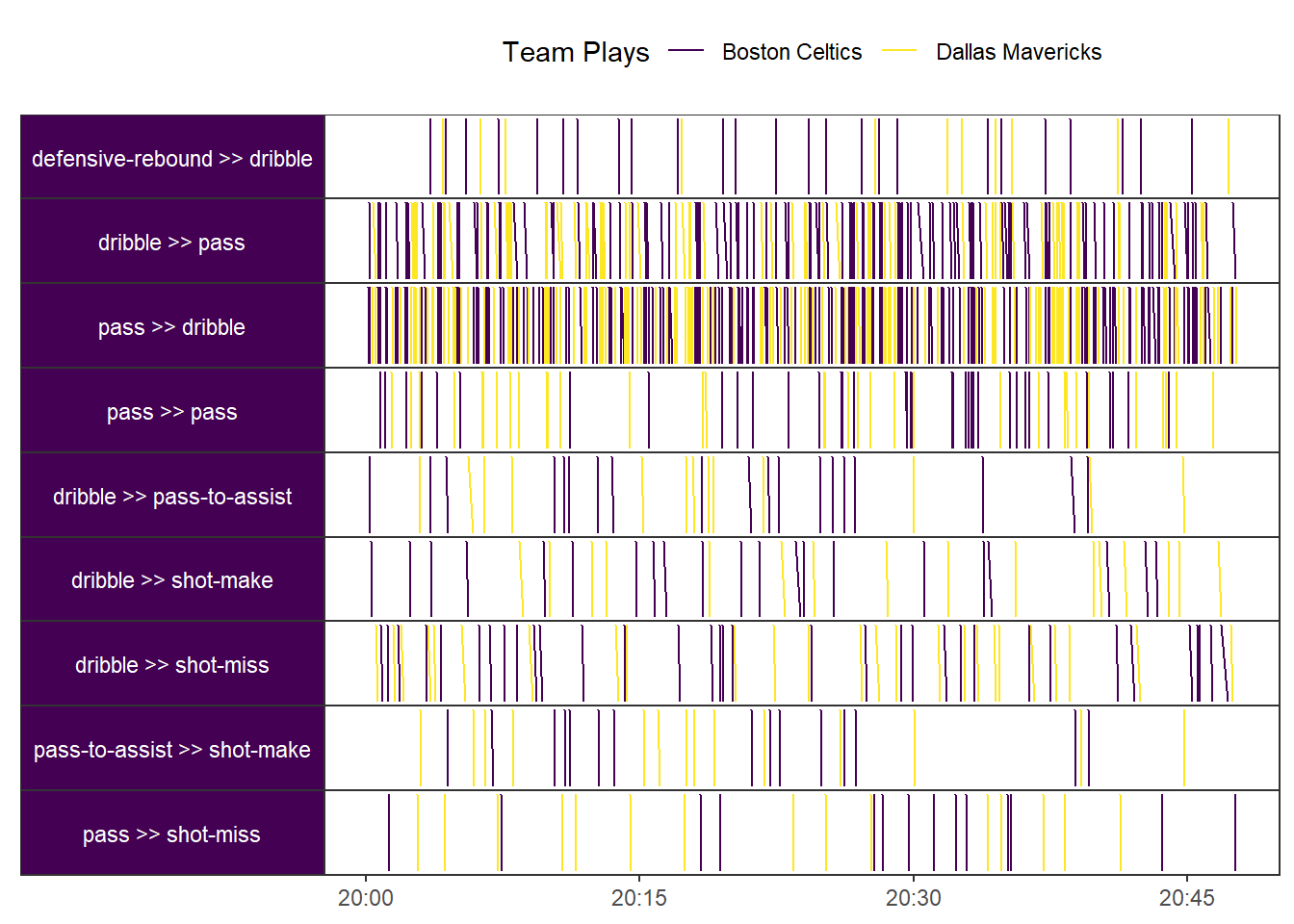
I have opted for 15% coverage of plays (or cases) as most would be sparse and beyond evaluating. In line with the taxonomy, this event has generally 2 elementary patterns:
-
For dribble to pass and vice versa: The pattern follows a single segment with globally occurring instances, with regular repetitions, and a continuous workload across the course of the event, the full 45 mins.
-
The rest of the pairwise segments had a similar taxonomy with a sparse workload.
Interesting analysis when applied to administrative data as is the case for Denisov, Fahland, and Aalst (2018). However offers little when applied to this dataset. If this dataset included off the ball movement and/or multiple games, perhaps analysis of performance spectra would be more fruitful.
Organisational
Organisational analysis refers to the examination of the social and organisational aspects of a business process, such as the resources, responsibilities, and interactions of the individuals involved.
Resource Industry
Looking at the top 10 industrious players, the players with higher frequency of activities. You would expect to see your star players at the top.
nba_final_g5_eventlog %>%
resource_frequency(level = 'resource') %>%
head(10) %>%
plot() +
theme(legend.position = 'none') +
scale_fill_viridis('Frequency',
option = 'D',
direction = -1) +
labs(title = 'Player Industriousness') +
xlab('')
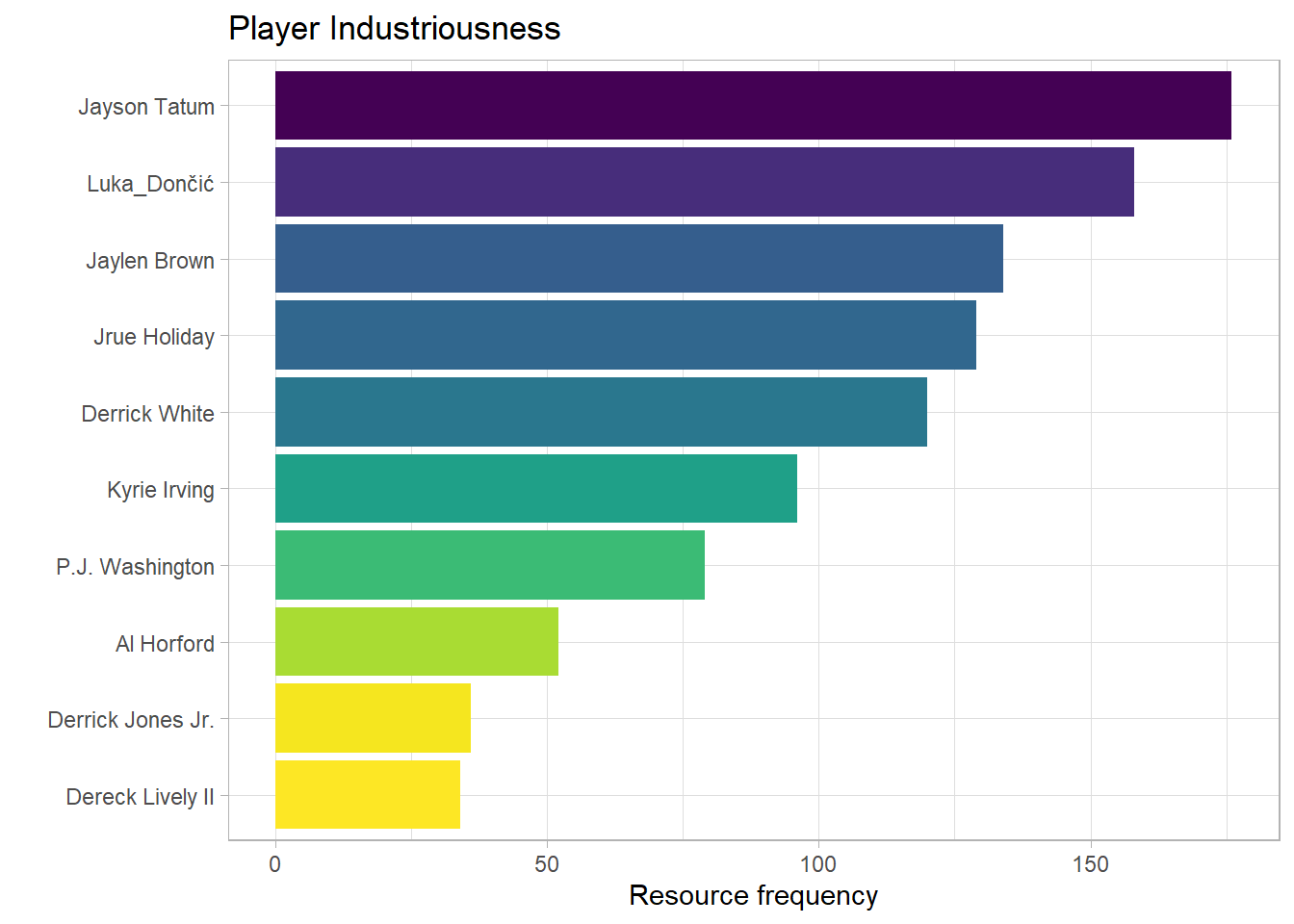
As you would expect, Tatum, Dončić, and Brown rank in the top 3. Irving was not as involved as Dallas would have liked. Boston hold 4 of the 5 top spots, they certainly brought the game to Dallas.
Specialisation
nba_final_g5_eventlog %>%
group_by(player_team) %>%
resource_frequency(level = 'resource-activity') %>%
filter(!resource_id %in% c('Boston Celtics', 'Dallas Mavericks'),
absolute > 1) %>%
plot() +
theme(legend.position = 'top') +
scale_fill_viridis(option = 'D', name = 'Relative Antecedence', direction = -1) +
ylab('')
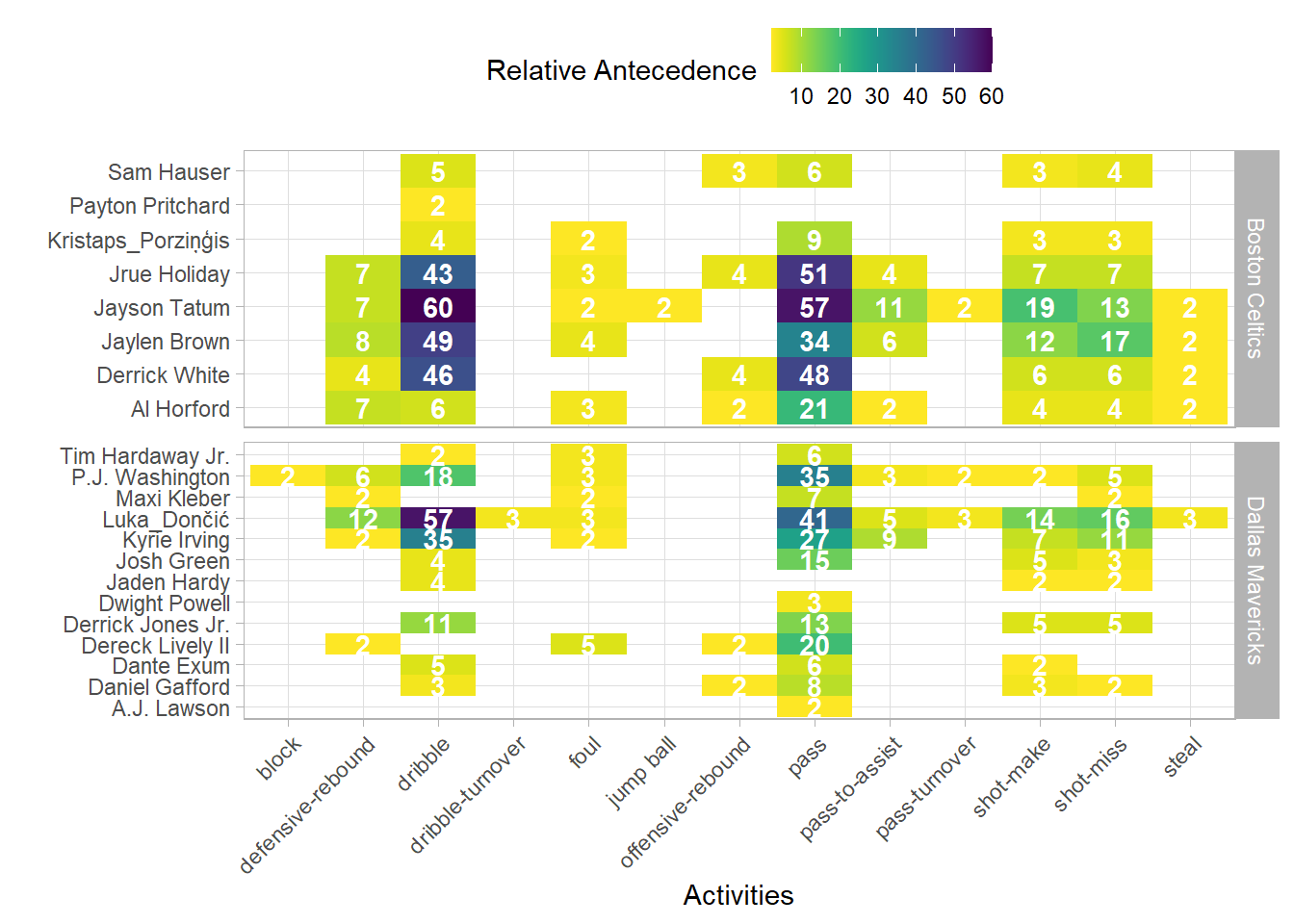
One game doesn’t make a specialist but for the purposes of exploration let us see who was a one-game specialist, who excels at a type of activity. Note, I have removed any activities that happened only once to reduce dimensions and make it easy viewing.
A few noteworthy insights
-
There are more Dallas players than Boston, the specialisation of activities was spread wider for Dallas.
-
Dončić held the pass master title for Dallas and was certainly his teams passing specialist whilst Boston shared that specialisation across 4 players.
-
Dončić specialised in defensive rebounds for his team as well as passing, were as Boston shared this responsibility across 4 players.
Although there were more Dallas specialists, Dončić was the main specialist in passing, and defensive rebounding comparative to his team whilst Boston often had several specialists in any given activity. This would have hindered Dallas when Dončić was subbed and benefited Boston during bench rotation.
Handover work
Handover analysis explores how work is handed off from one person or step to the next.
In the following resource maps, I will be looking at the 20% most frequent plays or traces.
Boston Celtics
nba_final_g5_eventlog %>%
mutate(resource_id = if_else(
resource_id == 'Jaylen Brown', 'J. Brown', resource_id)) %>%
filter(teams_play == 'Boston Celtics') %>%
filter_trace_frequency(percentage = 0.2) %>%
resource_map()
Jayson Tatum was passed to most (9) by Derrick White but only by 1 more pass. Followed by Jrue Holiday passing to Derrick White (8). Handover work is generally even across the most industrious players in Boston
Dallas Mavericks
nba_final_g5_eventlog %>%
filter(teams_play == 'Dallas Mavericks') %>%
filter_trace_frequency(percentage = 0.2) %>%
resource_map()
Comparative to Boston, Dallas rotated the basketball less. The highest handover score between players being 3.
For at least 20% of the most frequent plays, Boston moved the ball more, this is almost always a good sign in basketball, it often equates to:
- Improved player engagement
- Players better attuned to game tempo
- Players warm up quicker, essential for a sport which has constant substitutions
Conclusion
Game
Game 5 of the NBA 2024 finals had high variance in plays, with Boston winning the game. Boston was more industrious, their star players were more effective, were quicker at getting the shot up after defensive rebounds, moved the ball quicker, and had better rotation of the ball than Dallas.
Dallas really were never in the game, being thwarted whenever they mounted an attack. Dallas were unable to get Irving into the game, relied too much on Dončić, and were second best.
Method
Process mining applied to basketball has shown clear and easily digestible insights into the behaviours of both teams. That being said there is no open dataset well fitted towards this analysis for public use. I had to heavily enrich traditional play-by-play data. This time resource intensive approach, albeit as a personal project, means I will unlikely gather more data despite the analysis benefitting from it.
Further analysis into evasion sports like basketabll could look into including off the ball activity for process mining analysis, in this vein, perhaps individual sports would prove easier requiring less data to generate insight. Either way, the automating of data collection specific and open for the purpose of process mining would spearhead this type of analysis.
Specific to this case, having included, as an activity, when players don’t move with the ball. This would have been interesting to delve into. I suspect you would see the time Celtics held the ball increase in quarter 4 as they attempt to run the clock.
Acknowledgements
Packages and package maintainer(s):
- tidyverse | Hadley Wickham
- bupaverse | Gert Janssenswillen
- patchwork | Thomas Lin Pedersen
- viridis | Simon Garnier
- DT | Joe Cheng
- psmineR | Gert Janssenswillen
References
bupaverse. 2024. “BupaR Docs | Performance Spectrum — Bupaverse.github.io.” https://bupaverse.github.io/docs/performance_spectrum.html.
Denisov, Vadim, Dirk Fahland, and Wil Aalst. 2018. “Unbiased, Fine-Grained Description of Processes Performance from Event Data: 16th International Conference, BPM 2018, Sydney, NSW, Australia, September 9–14, 2018, Proceedings.” https://doi.org/10.1007/978-3-319-98648-7_9.
Kröckel, Pavlina, and Freimut Bodendorf. 2020. “Process Mining of Football Event Data: A Novel Approach for Tactical Insights into the Game.” Frontiers in Artificial Intelligence. https://doi.org/10.3389/frai.2020.00047.
nba.com/box-score. 2024. “Dallas Mavericks Vs Boston Celtics Jun 17, 2024 Box Scores — Nba.com.” https://www.nba.com/game/dal-vs-bos-0042300405/box-score?period=All.
nba.com/play-by-play. 2024. “Dallas Mavericks Vs Boston Celtics Jun 17, 2024 Play-by-Play — Nba.com.” https://www.nba.com/game/dal-vs-bos-0042300405/play-by-play?period=All.
- Posted on:
- September 11, 2024
- Length:
- 14 minute read, 2785 words
- Categories:
- package-exploration
- Tags:
- bupaverse sports-analytics rstats
- See Also:
- Rolling 5-year Sum Label Using `slider`